Assignment 3 Spatial Data
Intro
For this Spatial Data assignment, I have decided to work with Source #3 - Travel Guide to Chennai. I chose this source because having an accurate visualization of tourist places is crucial, based on my personal experience. When my friends and I had a spring break, we visited X country and it was complicated for us to create a good roadmap of places and understand how to navigate various locations efficiently in terms of time and cost. I believe attempting to visualize a travel guide will help understand how useful this can be for day-to-day life. In the future, I would love to see a tool that creates a recommendation system based on the places you input and displays the best route. The visualization we are working on now is a big step for this system, as finding paths and determining the best-cost routes for user inputs can be delegated to various algorithms. One of these algorithms is Dijkstra’s algorithm, which is used to find the shortest path.
Source
The Travel Guide to Chennai provides a brief overview of various places to visit, a general overview of the city, and essential facilities such as parks, hospitals, shops, etc. Everything a tourist needs when visiting.
Although the Travel Guide is not very long, I think it is possible to parse everything and create a comprehensive visual illustration. However, I decided to focus on some common places that tourists would likely want to hear about. Therefore, I chose to gather data about all hospitals, movie theaters, and amusement parks. I believe this is a good proportion of what might be needed in emergency cases and for entertainment.
Below we can see brief overview of the data:

Data Preparation
With the given data, our first step is to utilize Optical Character Recognition (OCR) to obtain the required format of the text. Afterward, we can use some regex patterns to extract phone numbers and the names of the places. However, I think Language Models (LLMs) like ChatGPT can perform this task much faster and accurately. Using regex involves considering a vast number of edge cases, making it a time-consuming process. So, I fed my raw data to ChatGPT and asked it to create a CSV format needed for further operations. Since data like phone numbers and addresses could have multiple comma-separated entries, I asked ChatGPT to use a custom delimiter, **, to save time correcting errors later:
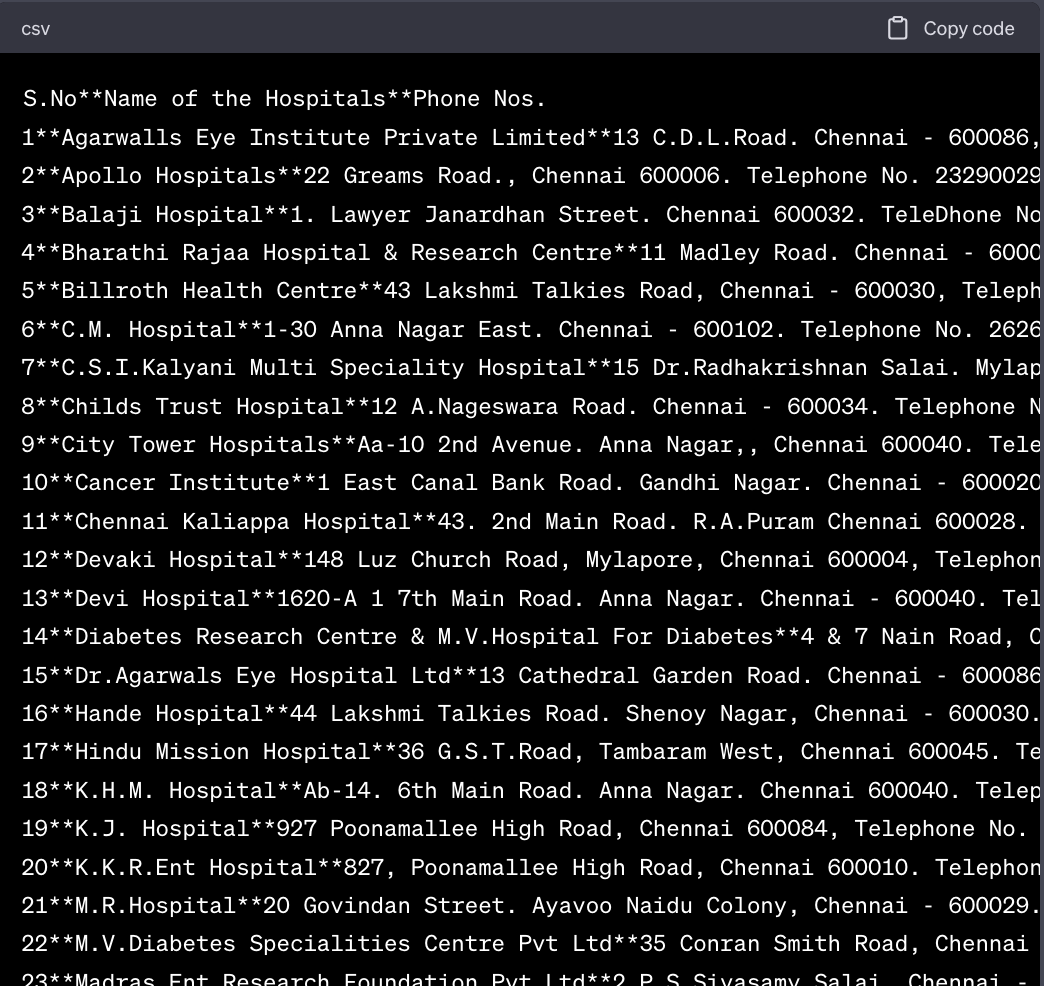
The process of obtaining expected results from ChatGPT may not always be successful, so it is important to engage in robust prompt engineering. If the input data is messy, providing additional information can help the language model (LLM) improve its output. In our case, I decided to generally explain the nature of the data, the types of data we have, possible columns, and outline different edge cases. For example, we could have multiple entries for the phone field, etc.
Next, I imported the CSV files into Excel with the custom delimiter. Using the geoCode extension, I started fetching longitude and latitude data. This data preparation is for our visualization tool, Kepler.gl. We obtained three various CSV files for various categories of places: hospitals, parks, and movie theaters:



I decided to keep them separate as it will allow us to use Kepler tool’s features to separately adjust some parameters for each cluster.
Visualization
After importing CSV files, we get the following illustration:
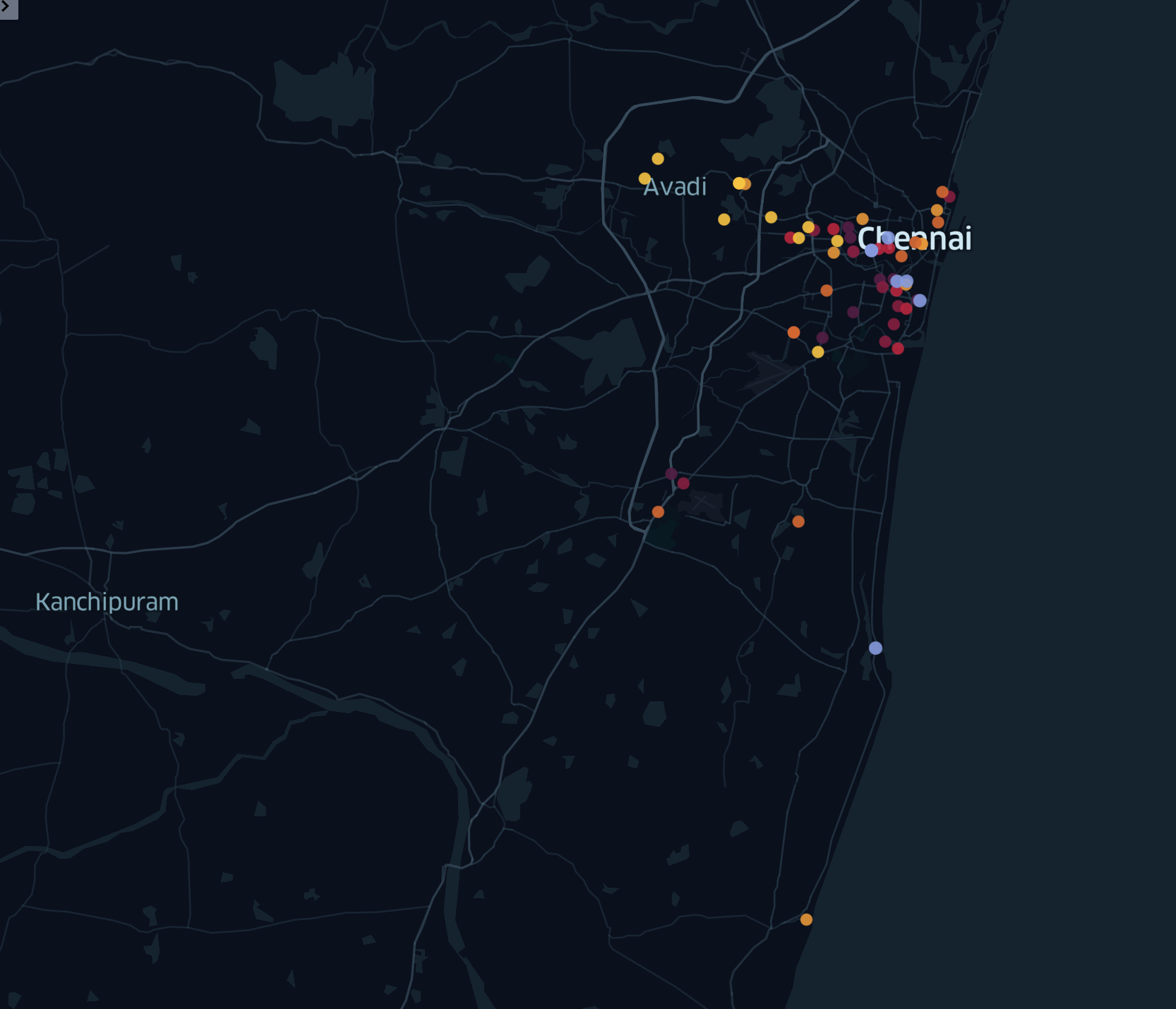
Each cluster is determined by its color, and we can draw polygons for better visualization. Potentially, this tool can be used as a suggestion system that will try to pick places by reducing travel costs and distances among them.
Polygon of amusement park connections:
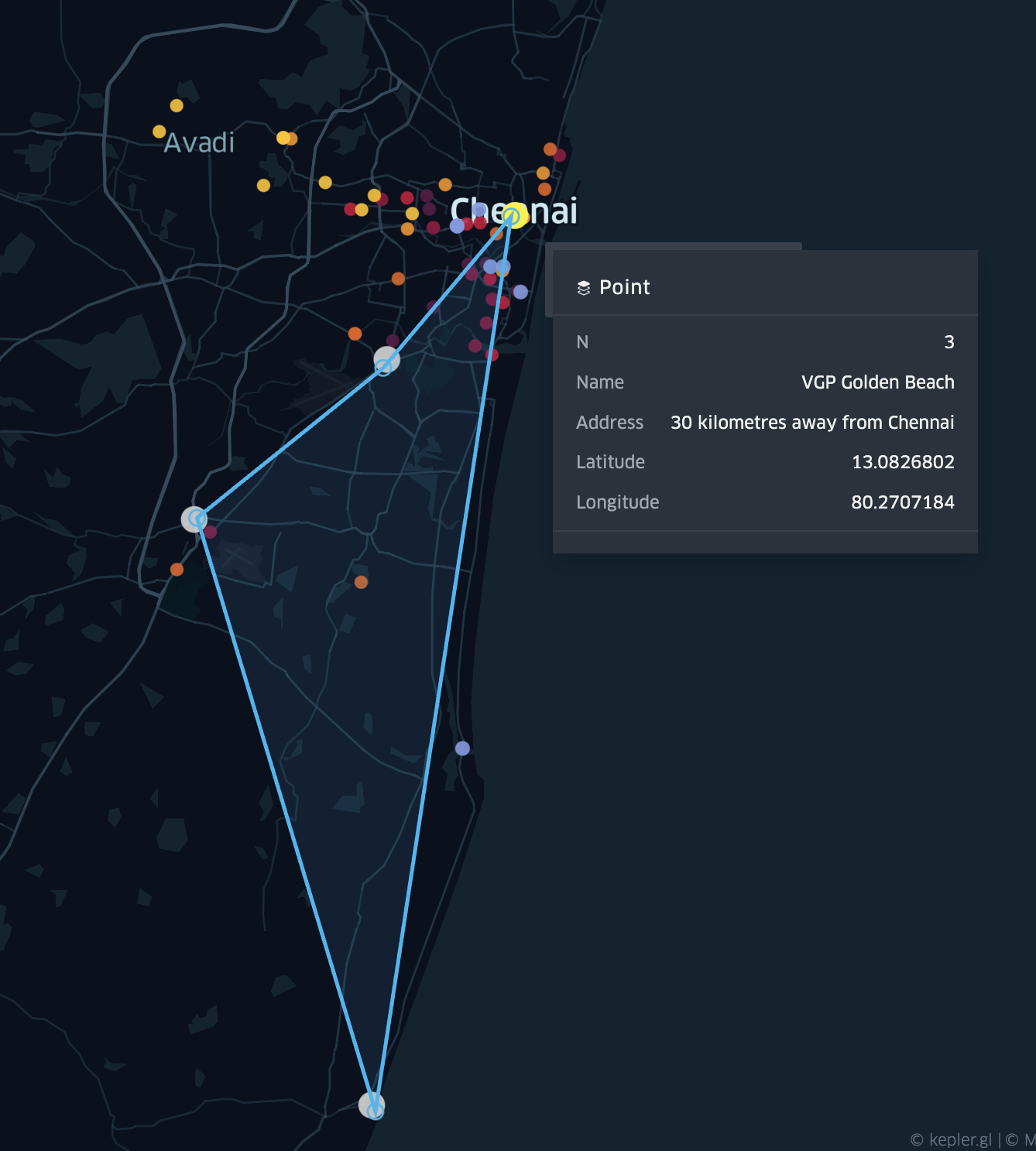
Coverage area of All places(polygon):
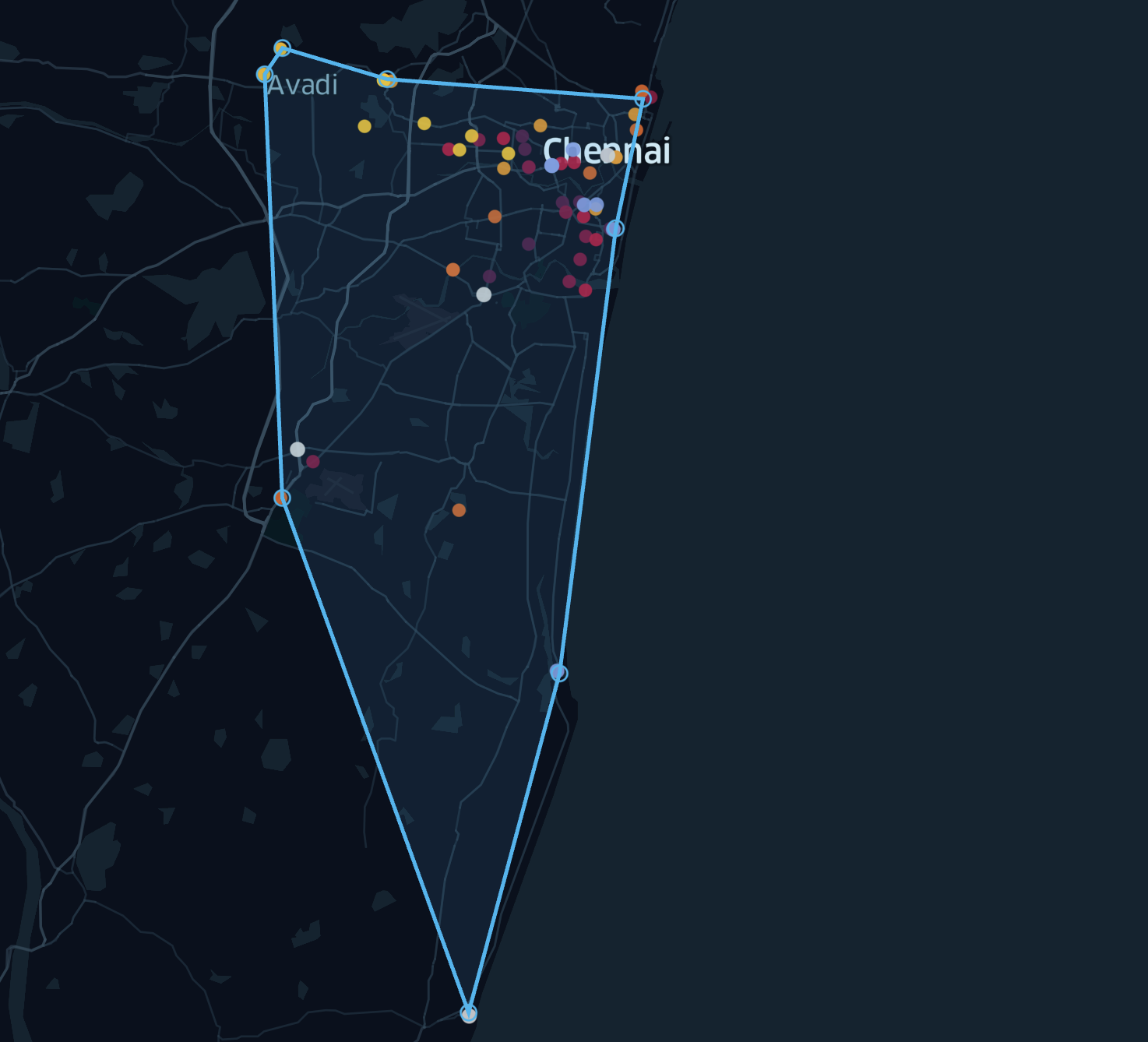
With the help of the visualization, we easily identified an “outlier” (wrong data), that was later removed from the data: